Nephele Execution Engine
Stratosphere is a stack of the Nephele execution engine, the PACT runtime, and the Java and Scala front ends.
Architecture Overview
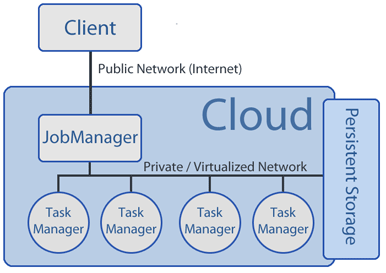
Before submitting a Nephele compute job, a user must start an instance inside the cloud which runs the so called Job Manager. The Job Manager receives the client’s jobs, is responsible for scheduling them and coordinates their execution. It can allocate or deallocate virtual machines according to the current job execution phase. The actual execution of tasks is carried out by a set of instances. Each instance runs a local component of the Nephele framework (Task Manager). A Task Manager receives one or more tasks from the Job Manager at a time, executes them and informs the Job Manager about their completion or possible errors. Unless a job is submitted to the Job Manager, we expect the set of instances (and hence the set of Task Managers) to be empty. Upon job reception, the Job Manager decides depending on the particular tasks inside a job, how many and what kind of instances the job should be executed on. It also decided when respective instances must be allocated or deallocated in order to ensure a continuous but cost-efficient processing.
For details on the architectural components, refer to the following sections:
- JobManager
- TaskManager
- Scheduler
- MemoryManager
- IOManager
- NepheleGUI
- Client
JobManager
In Nephele, the job manager is the central component for communicating with clients, creating schedules for incoming jobs, and supervising the execution of the jobs. A job manager may only exist once in the system and its address must be known to all clients. Task managers can discover the job manager by means of an UDP broadcast and then advertise themselves as new workers for tasks.
If a job graph is submitted from a client to the job manager, each task of the job will be sent to a task manager. The job manager periodically receives heartbeats from the task managers and propagates them to the instance manager. To supervise the execution of the job, each task manager sends information to the job manager about changes in the execution states of a task (e.g.: changing to FAILED).
TaskManager
A task manager receives tasks from the job manager and executes them. After having executed them (or in case of an execution error) it reports the execution result back to the job manager. Task managers are able to automatically discover the job manager and receive its configuration when the job manager is running on the same local network. The task manager periodically sends heartbeats to the job manager to report that it is still running.
Interface
The task manager implements the
TaskOperationProtocol
interface which is defined as part of the nephele-server project in
the package
eu.stratosphere.nephele.protocols.
It provides methods for the job manager to submit and cancel tasks, as
well as to query the task manager for cached libraries and submit these
if necessary.
Memory Manager
Paged Memory Abstraction
The MemoryManager interface is defined as part of the nephele-common
project in the package
eu.stratosphere.nephele.services.memorymanager.
Memory is allocated in
MemorySegments,
which have a certain fixed size and are also referred to as memory
pages. The segments themselves can randomly access data at certain
positions as certain types (int, long, byte[], …).
All memory that is allocated in a task is bound to that specific task. Once the task ends, no matter whether successful or not, the TaskManager releases all memory the task had allocated, clearing any internal references of the memory segments, such that any subsequent access to the memory results in a NullPointerException.
Memory Views
More typically than directly accessing the memory pages, the data is accessed though views: DataInputView and DataOutputView. The provide the abstraction of writing (or reading) sequentially to (from) memory. Underneath, the data is distributed across the memory pages.
Most memory views inherit from AbstractPagedInputView and AbstractPagedOutputView. There are view implementations which transparently flush pages to disk and retrieve them again when memory is scarce.
Default Memory Manager
Nephele provides a
DefaultMemoryManager.
It is started with a certain memory size. The size may be exactly
specified (in megabytes) in the Nephele configuration via the parameter
taskmanager.memory.size (see Configuration
Reference).
If the taskmanager.memory.size parameter is not specified, the
TaskManager instantiates the MemoryManager with a certain ratio of its
remaining memory. That amount is determined after all other Nephele
services have started and allocated their memory.
Internally, the memory manager reserves the memory by allocating byte arrays upon startup time. At runtime it only distributed and re-collects those byte arrays.
I/O Manager
The I/O manager is Nephele's component that should be used by user programs to write data to disk and read data back. The purpose is to create a single I/O gateway to avoid too many concurrent reading and writing threads and to allow asynchronous I/O operations, including pre-fetching and write-behind. The I/O manager has a single thread for serving read requests and one for write requests. Internally, I/O operations are always performed in units of blocks. The memory used by the I/O manager is in the form of memory segments from the MemoryManager.
The I/O manager and the readers and writers are contained in the package eu.stratosphere.nephele.services.iomanager. The I/O manager provides only abstractions for reading / writing entire memory pages. Abstractions for record streams are given though ChannelReaderInputView and ChannelWriterOutputView.
The files creates by the I/O manager are temporary files that live only in the scope of one job. They are by default created in the system's temp directory and are described by channel IDs, which encapsulate their path. The path of the temp files is configured with the parameter taskmanager.tmp.dir. Refer to the Configuration Reference for details.
Block Channels
Block channels are instantiated with a channel ID (an internal id for the file path) and a synchronized queue that is a source or drain of buffers. The BlockChannelWriter for example accepts memory segments (blocks), writes them as soon as possible, and returns the memory block that was written to the given queue. If the same queue is used to draw the next required memory segments from, that mechanism realizes block write-behind I/O simply and efficiently. The key difference to the stream channels is that blocks are not owned exclusively by a channel during its life time.
Developing Nephele Jobs
Although we encourage programmers to use the PACT programming model for their data analysis jobs, it is also possible to define and develop programs at the Nephele layer.
At the Nephele layer, programs are defined as directed acyclic graphs (DAGs). Each vertex of the DAG represents a particular task of the overall processing job. Three types of vertices exist:
- Input Vertices
- Task Vertices
- Output Vertices
Input and Output Vertices are pure data sources resp. data sinks. These vertices read or write data from or to the disk. Task Vertices are the part of a Nephele Job where the actual user code is being executed. Vertices are connected to each other by edges. The edges denote the communication channels between the tasks.
Consequently, writing a Nephele program requires two distinct steps: First, selecting/writing the particular tasks of the overall processing job and second, assembling them to a so-called job graph.

Writing a Basic Nephele Task
In general, each Nephele task is expected to constitute a separate
Java class. In the following we will create an exemplary class with the
name ExampleTask to illustrate the process. To be executed by the
Nephele framework, the vertex class must extend either AbstractTask,
AbstractInputTask, or AbstractOutputTask (or one of their subtypes).
The right parent class depends on the vertex of the job graph to which
the task is attached later on.
Tasks derived from AbstractInputTask or AbstractOutputTask are only allowed to have either incoming or outgoing edges, respectively. Nephele provides default implementations for file I/O. Classes derived from AbstractTask represent Task Vertices in a Nephele job graph and hence they must be attached to a vertex which has incoming and outgoing edges later on.
public class ExampleTask extends AbstractTask {
@Override
public void registerInputOutput() {
}
@Override
public void invoke() throws Execution {
}
}
As a result of the inheritance from AbstractTask two methods must be implemented: registerInputOutput and invoke. The first method, registerInputOutput, is responsible for initializing the input and output gates the tasks will send and receive data from. These gates will later be connected via channels. The number of input gates must match the number of incoming and outgoing edges as defined for the corresponding vertex in the job graph.
public class ExampleTask extends AbstractTask {
private RecordReader<StringRecord> input = null;
private RecordWriter<StringRecord> output = null;
@Override
public void registerInputOutput() {
this.input = new RecordReader<StringRecord>(this, StringRecord.class, null);
this.output = new RecordWriter<StringRecord>(this, StringRecord.class);
}
@Override
public void invoke() throws Exception {
}
}
The task ExampleTask defines one input and one output gate. Gates are typed to as specific data type and can only send or receive data of that type. The type of data is determined upon the initialization of the so-called RecordReader or RecordWriter objects, which represent the gate endpoints within the task. Nephele provides default record types for Strings, Integers and Files. For details on how to implement custom data types, see section below.
Input and Output gates are identified by a gate ID. When connecting tasks with multiple Input and Output gates, this ID can be used to connect multiple gates accordingly. Each Task has two sets of gate IDs (Input/Output). The constructor of RecordReader allows to explicitly specify the gate ID. Gates must be numbered using Integers starting at zero. If (as in this case) the constructor is called without gate ID, the next free gate ID (starting at zero) will be assigned.
The second method a developer of a Nephele task must override the the invoke method. The invoke method resembles the run method of a Java thread. It contains the code that is executed at the task's runtime. Usually, Nephele tasks read data from at least one input gate, process it, and pass the processed data via one or more output gates. We extended the example below to continuously read incoming records of type StringRecord and immediately pass them on the output gate.
public class ExampleTask extends AbstractTask {
private RecordReader<StringRecord> input = null;
private RecordWriter<StringRecord> output = null;
@Override
public void registerInputOutput() {
this.input = new RecordReader<StringRecord>(this, StringRecord.class, null);
this.output = new RecordWriter<StringRecord>(this, StringRecord.class);
}
@Override
public void invoke() throws Execution {
while(input.hasNext()) {
StringRecord str = input.next();
output.emit(str);
}
}
}
The programming interface of input gates resembles classic iterators in Java. The method hasNext indicates whether further data can be read, the method next retrieves the data and increases the iterator.
Connecting Tasks to a Job Graph
The following code illustrates how individual tasks can be connected to a so-called Job Graph. The Job Graph defines the actual dependencies of the overall job. It specifies the routes that records flow through the system at runtime.
public class ExampleJob {
public static void main(String [] args) {
JobGraph jobGraph = new JobGraph("Example Job");
JobFileInputVertex input = new JobFileInputVertex("Input 1", jobGraph);
input.setFileInputClass(FileLineReader.class);
input.setFilePath(new Path("file:///tmp/input.txt"));
JobTaskVertex forwarder = new JobTaskVertex("Forwarder", jobGraph);
forwarder.setTaskClass(ExampleTask.class);
JobFileOutputVertex output = new JobFileOutputVertex("Output 1", jobGraph);
output.setFileOutputClass(FileLineWriter.class);
output.setFilePath(new Path("file:///tmp/output.txt"));
try {
input.connectTo(forwarder, ChannelType.NETWORK, null);
forwarder.connectTo(output, ChannelType.FILE, null);
} catch(JobGraphDefinitionException e) {
e.printStackTrace();
return;
}
jobGraph.addJar(new Path("file:///tmp/example.jar"));
Configuration clientConfiguration = new Configuration();
clientConfiguration.setString("jobmanager.rpc.address", "192.168.198.3");
try {
JobClient jobClient = new JobClient(jobGraph, clientConfiguration);
jobClient.submitJobAndWait();
} catch (IOException e) {
e.printStackTrace();
}
}
}
The example Job Graph consists of three vertices, a data source task, a processing task, and a data sink task.
- The first vertex input reads the input file file:/tmp/input.txtline by line and emits each line as a separate string record. \ The second vertexforwarderexecutes the example taskExampleTaskwe have previously developed. * The third taskoutputwrites the received string records to the output filefile:/tmp/output.txt*.
The method connectTo creates a directed edge between from a vertex and another vertex. In the example the vertex input is connected to the vertex forwarder. The vertex forwarder, is connected to the vertex output. Each edge will be transformed into one or more communication channels at runtime which physically transport the records from one task to the other. If multiple input and output gates are used, this method can also be parametrized with the corresponding gate IDs.
Currently, Nephele supports three different channel types, FILE, NETWORK, and INMEMORY channels. Each channel type has different implications on Nephele's scheduling strategy. Please consider Nephele: Efficient Parallel Data Processing In The Cloud for details on this subject.
An important issue is to understand how Nephele deploys user code at runtime. In order to execute a job correctly, the required user code must be submitted with the Job Graph to Nephele. The user code is expected to be packaged in a Java JAR-file and attached to the Job Graph. In the example above the line
jobGraph.addJar(new Path("file:///tmp/example.jar"));
is responsible for that. The user code is expected to be included in the JAR-file /tmp/example.jar.
Customizing Tasks
The previous example showed an easy example of a JobGraph without applying any further options. In this section, additional options that can be applied to a JobGraph are listed.
Setting the Number of Subtasks
Nephele allows a task vertex to be split (duplicated) to an arbitrary number of subtasks which are scheduled and executed in parallel. The number of subtasks can be set during creation of the JobGraph using the following method call:
forwarder.setNumberOfSubtasks(4);
Nephele will split the String forwarder task into four subtasks and take care of the complex channel management.
Limiting the Number of Subtasks
In some situations, the developer of a task must ensure, that the corresponding job vertex should not be split into more than one subtask. This might occur, when at a certain position in the JobGraph the ordering of input and output values must be kept in exact sequence. From the user-code, it is therefore possible to set a minimum/maximum value for the number of subtasks, the actual task must or must not be split into. This can be achieved by overriding the methods getMinimumNumberofSubtasks() resp. getMaximumNumberofSubtasks(). A violation of these constraints (setting a higher/lower number of subtasks when creating the JobGraph) will cause an error and prevent the Nephele job from being executed.
public class ExampleTask extends AbstractTask {
...
@Override
public int getMinimumNumberOfSubtasks() {
//The default implementation always returns 1
return 1;
}
@Override
public int getMaximumNumberOfSubtasks() {
//The default implementation always returns -1 (unlimited number of subtasks)
return 1;
}
...
}
Passing Additional Configuration Parameters to a Task
Parameterization significantly improves the reusability of source code. Nephele features configuration parameters for tasks. Parameters are set when assembling the JobGraph and used during execution time. In our simple example, we pass a String configuration parameter to all forwarder tasks. The parameter is as a filter constant such that only lines are forwarded that contain the provided String.
Each Nephele Job has a Configuration class that can be accessed both from within the user-code as well as from the code that generates the JobGraph. The Configuration can be used to set and share values of common data types (Boolean, Integer, String). The configuration is realized as a map, a configuration parameter is identified by a key (String) and a corresponding value. From the code that generates the JobGraph, Configuration parameters can be set using:
forwarder.getConfiguration().setString("key.lineswearelookingfor", "Foo");
From within the user code, configuration parameters can be accessed using the Method getRuntimeConfiguration():
public class ExampleTask extends AbstractTask {
...
public void invoke() throws Execution {
...
String s = getRuntimeConfiguration().getString("key.lineswearelookingfor", "defaultvalue");
...
}
...
}
The configuration is also available to the task at initialization time (within the constructor).
Configuration Check
In case a developer of a task wants to perform some configuration check after the user's class has been instantiated and the method registerInputOutput() was called, one can override the method checkConfiguration. The Nephele system will call this method always before the invoke() method.
public class ExampleTask extends AbstractTask {
...
@Override
public void checkConfiguration() throws IllegalConfigurationException {
if(anythingwentwrong){
throw new IllegalConfigurationException("something went wrong!");
}
//The default implementation does nothing
}
...
}
Throwing an IllegalConfigurationException will prevent the code from being executed and cause the job to fail.
Understanding Events
Job tasks in Nephele exchange data in the form of Records of a specified data type. This type of communication is intended to exchange actual user data. To exchange other types of information (primarily status information), Nephele offers an Event framework. Custom Events can be fired (sent) bidirectional between any job tasks that are connected to each other. Events are processed and transferred between tasks immediately.
Note: Events fired across Channels that rely on a byte buffer (network and file channels) will always cause the whole buffer to be flushed in order to achieve immediate transmission. When using byte-buffered channels, Events should be used in a parsimonious manner. Frequent flushing of non-full buffers leads to lower throughput.
Nephele provides two simple default implementations for Events: StringTaskEvent and IntegerTaskEvent. These events carry one value (Integer, String). Customized Events can be created by inheritance of the class AbstractTaskEvent (see Section Using customized data types)
Firing Events
Events can be fired within the user code by simply calling an input or output gate's publishEvent method.
public class ExampleTask extends AbstractTask {
...
@Override
public void invoke() throws Exception{
...
this.output.publishEvent(new StringTaskEvent("this is a simple event message"));
}
...
}
Subscribing to Events
In order to be able to receive events, and event listener implementing the interface EventListener (not java.util.EventListener but the one from Nephele)
eu.stratosphere.nephele.event.task.EventListener must be provided.
import eu.stratosphere.nephele.event.task.EventListener;
public class MyEventListener implements EventListener {
@Override
public void eventOccurred(AbstractTaskEvent event) {
if (event instanceof StringTaskEvent) {
System.out.println("Message Event received: " + ((StringTaskEvent) event).getString());
}
}
}
Note: Make sure to include the event listener class in the .jars for deployment. Inner classes cannot be used here!
Now, as we have our event listener, we can subscribe the desired type of event, we want to receive:
public class ExampleTask extends AbstractTask {
...
@Override
public void registerInputOutput() {
...
this.input.subscribeToEvent(new MyEventListener(), StringTaskEvent.class);
...
}
...
}
Parallelization of File Input/Output
JobFileInput and JobFileOutput vertices can read and write data sets to files. The default classes for input and output are FileLineReader resp. FileLineWriter (as seen in the simple example above). The Record type used by these classes is StringRecord, which represents one line in a file.
Parallelized File Reading
When reading from a local file system and a single file, no parallelization is possible. If the file path points to a directory (instead of a single file), Nephele will read all files contained in the directory (non-recursive). By increasing the number of subtasks of the corresponding JobFileInputVertex, Nephele will read from multiple files in parallel.
When reading from a HDFS file system, both reading from a directory, as well as reading from a single file can be done concurrently by increasing the number of subtasks for the certain JobFileInputVertex.
Parallelized File Writing
When writing to single file, no parallelization is possible. This applies both for local, as well as for distributed files. It is possible to parallelize file writing by pointing the file output path to a directory instead of a single file. In this case, Nephele will write to as many files as subtasks for the JobFileOutput vertex exist. Files will be named file_NUMBEROFSUBTASK.txt.
Customizing Data Types
Any objects in Nephele, that need to be transferred between two tasks via channels must be serializable even though no serialization takes place in case of INMEMORY channels.
This is particularly of importance, if you plan to develop custom Record types or Events. All abstract classes/interfaces provided for custom Records (interface: eu.stratosphere.nephele.types.Record) or custom Events (abstract class: eu.stratosphere.nephele.event.task.AbstractTaskEvent) implement or inherit the interface IOReadableWritable. Hence, a write(DataOutput out) and a read(DataInput in) method must be implemented for custom Records and Events.
These two methods are used to serialize/deserialize any object and must be implemented by the developer itself. These methods must write/read all relevant object data (attributes) to/from the given data stream. See an example for and implementation of the StringTaskEvent:
public class StringTaskEvent extends AbstractTaskEvent {
private String message = null;
public StringTaskEvent() {
//a parameterless constructor MUST be present if serialization is used!
}
public StringTaskEvent(String message) {
this.message = message;
}
public String getString() {
return this.message;
}
@Override
public void write(DataOutput out) throws IOException {
if (this.message == null) {
out.writeInt(0);
} else {
byte[] stringbytes = this.message.getBytes("UTF8");
out.writeInt(stringbytes.length);
out.write(stringbytes);
}
}
@Override
public void read(DataInput in) throws IOException {
final int length = in.readInt();
if(length > 0){
byte[] stringbytes = new byte[[length]];
in.readFully(stringbytes, 0, length);
String message = new String(stringbytes, "UTF8");
this.message = message;
}else{
this.message = null;
}
}
}
The above example shows a simple entity class, holding a String value in the attribute message. The write/read methods serialize and deserialize the members or fields of an object. The during deserialization, the type of the object is already determined and the (empty) object has already been created with a parameter-less (default) constructor which must be implemented as well. The call of the read method shall fill the (probably empty) object with the deserialized values.
DataInput and DataOutput are binary streams. When read/write is called, you can expect that you start to read/write at the position in the stream that holds the serialized attribute data. Read and write must correspond, such that the same amount of data (number of bytes) is written as is read. A violation of this will cause in severe errors.
In the upper example, the data type we want to serialize is a String. Hence, the actual length (in terms of numbers of bytes) varies over different objects. We take care of this by first writing/reading the total number of bytes our payload consists of. An integer is a primitive data type (fixed size in terms of bytes). Therefore, it can be read and written it as fixed block. Then, we can read the arbitrary number of bytes that represent our String value. Using this, we can guarantee that when deserializing the object, we read the exact number of bytes as were written before.