PACT Runtime
Stratosphere is a stack of the PACT runtime, the Nephele execution engine, and the Java and Scala front ends.
PACT is a parallel programming model and extends MapReduce. PACT provides a user API to write parallel data processing tasks. Programs written in the PACT programming model are translated by the PACT Compiler into a Nephele job and and executed on Nephele. In fact, Nephele considers PACT programs as regular Nephele jobs; to Nephele, PACT programs are arbitrary user programs.
The PACT Programming Model
PACT and MapReduce
The PACT programming model is a generalization of the MapReduce programming model. In the following, we briefly introduce the MapReduce programming model and highlight the main differences to the PACT programming model.
MapReduce Programming Model
The goal of the MapReduce programming model is to ease the development
of parallel data processing tasks by hiding the complexity of writing
parallel and fault-tolerant code. To specify a MapReduce job, a
developer needs to implement only two first-order functions. When a
MapReduce job is executed by a MapReduce framework, these user functions
are handed to the second-order functions map() and reduce(). The
framework takes care of executing the job in a distributed and
fault-tolerant way.
The user functions can be of arbitrary complexity. Both operate on
independent subsets of the input data which are build by the
second-order functions (SOFs) map() and reduce() (Data Parallelism).
MapReduce's data model is based on pairs of keys and values. Both, key
and value can be of any complex type and are interpreted only by the
user code and not by the execution framework.
PACT Programming Model
The PACT programming model is based on the concept of Parallelization Contracts (PACTs). Similar to MapReduce, arbitrary user code is handed and executed by PACTs. However, PACT generalizes a couple of MapReduce's concepts:
- Second-order Functions: PACT provides more second-order functions. Currently, five SOF called Input Contracts are supported. This set might be extended in the future.
- Program structure: PACT allows the composition of arbitrary acyclic data flow graphs. In contract, MapReduce programs have a static structure (Map → Reduce).
- Data Model: PACT's data model are records of arbitrary many fields of arbitrary types. MapReduce's KeyValue-Pairs can be considered as records with two fields.
In the following, the concept of Parallelization Contracts is discussed and how they are composed to PACT programs.
What is a PACT?
Parallelization Contracts (PACTs) are data processing operators in a data flow. Therefore, a PACT has one or more data inputs and one or more outputs. A PACT consists of two components:
- Input Contract
- User function
- User code annotations
The figure below shows how those components work together. Input Contracts split the input data into independently processable subset. The user code is called for each of these independent subsets. All calls can be executed in parallel, because the subsets are independent.
Optionally, the user code can be annotated with additional information. These annotations disclose some information on the behavior of the black-box user function. The PACT Compiler can utilize the information to obtain more efficient execution plans. However, while a missing annotation will not change the result of the execution, an incorrect Output Contract produces wrong results.

The currently supported Input Contracts and annotation are presented and discussed in the following.
Input Contracts
Input Contracts split the input data of a PACT into independently processable subsets that are handed to the user function of the PACT. Input Contracts vary in the number of data inputs and the way how independent subsets are generated.
More formally, Input Contracts are second-order functions with a first-order function (the user code), one or more input sets, and none or more key fields per input as parameters. The first-order function is called (one or) multiple times with subsets of the input set(s). Since the first-order functions have no side effects, each call is independent from each other and all calls can be done in parallel.
The second-order functions map() and reduce() of the MapReduce
programming model are Input Contracts in the context of the PACT
programming model.
MAP
The Map Input Contract works in the same way as in MapReduce. It has a single input and assigns each input record to its own subset. Hence, all records are processed independently from each other (see figure below).

REDUCE
The Reduce Input Contract has the same semantics as the reduce function in MapReduce. It has a single input and groups together all records that have identical key fields. Each of these groups is handed as a whole to the user code and processed by it (see figure below). The PACT Programming Model does also support optional Combiners, e.g. for partial aggregations.

CROSS
The Cross Input Contract works on two inputs. It builds the Cartesian product of the records of both inputs. Each element of the Cartesian product (pair of records) is handed to the user code.

MATCH
The Match Input Contract works on two inputs. From both inputs it matches those records that are identical on their key fields come from different inputs. Hence, it resembles an equality join where the keys of both inputs are the attributes to join on. Each matched pair of records is handed to the user code.

COGROUP
The CoGroup Input Contract works on two inputs as well. It can be seen as a Reduce on two inputs. On each input, the records are grouped by key (such as Reduce does) and handed to the user code. In contrast to Match, the user code is also called for a key if only one input has a pair with it (see blue key in example below).

Pact Record Data Model
In contrast to MapReduce, PACT uses a more generic data model of records (Pact Record) to pass data between functions. The Pact Record can be thought of as a tuple with a free schema. The interpretation of the fields of a record is up to the user function. A Key/Value pair (as in MapReduce) is a special case of that record with only two fields (the key and the value).
For input contracts that operate on keys (like Reduce, Match, or CoGroup, one specifies which combination of the record's fields make up the key. An arbitrary combination of fields may used. See the TPCH Query Exampe on how programs defining Reduce and Match contracts on one or more fields and can be written to minimally move data between fields.
The record may be sparsely filled, i.e. it may have fields that have null values. It is legal to produce a record where for example only fields 2 and 5 are set. Fields 1, 3, 4 are interpreted to be null. Fields that are used by a contract as key fields may however not be null, or an exception is raised.
User code annotations
User code annotation are optional in the PACT programming model. They allow the developer to make certain behaviors of her/his user code explicit to the optimizer. The PACT optimizer can utilize that information to obtain more efficient execution plans. However, it will not impact the correctness of the result if a valid annotation was not attached to the user code. On the other hand, invalidly specified annotations might cause the computation of wrong results. In the following, we list the current set of available Output Contracts.
Constant Fields
The Constant Fields annotation marks fields that are not modified by the user code function. Note that for every input record a constant field may not change its content and position in any output record! In case of binary second-order functions such as Cross, Match, and CoGroup, the user can specify one annotation per input.
Constant Fields Except
The Constant Fields Except annotation is inverse to the Constant Fields annotation. It annotates all fields which might be modified by the annotated user-function, hence the optimizer considers any not annotated field as constant. This annotation should be used very carefully! Again, for binary second-order functions (Cross, Match, CoGroup), one annotation per input can be defined. Note that either the Constant Fields or the Constant Fields Except annotation may be used for an input.
PACT Programs
PACT programs are constructed as data flow graphs that consist of data sources, PACTs, and data sinks. One or more data sources read files that contain the input data and generate records from those files. Those records are processed by one or more PACTs, each consisting of an Input Contract, user code, and optional code annotations. Finally, the results are written back to output files by one or more data sinks. In contrast to the MapReduce programming model, a PACT program can be arbitrary complex and has no fixed structure.
The figure below shows a PACT program with two data sources, four PACTs, and one data sink. Each data source reads data from a specified location in the file system. Both sources forward the data to respective PACTs with Map Input Contracts. The user code is not shown in the figure. The output of both Map PACTs streams into a PACT with a Match Input Contract. The last PACT has a Reduce Input Contract and forwards its result to the data sink.

Advantages of PACT over MapReduce
- The PACT programming model encourages a more modular programming style. Although the number of user functions is usually higher, they are more fine-grain and focus on specific problems. Hence, interweaving of functionality which is common for MapReduce jobs can be avoided.
- Data analysis tasks can be expressed as straight-forward data flows, especially when multiple inputs are required.
- PACT has a record-based data model, which reduces the need to specify custom data types as not all data items need to be packed into a single value type.
- PACT frequently eradicates the need for auxiliary structures, such as the distributed cache, which “break” the parallel programming model.
- Data organization operations such as building a Cartesian product or combining records with equal keys are done by the runtime system. In MapReduce such often needed functionality must be provided by the developer of the user code.
- PACTs specify data parallelization in a declarative way which leaves several degrees of freedom to the system. These degrees of freedom are an important prerequisite for automatic optimization. The PACT compiler enumerate different execution strategies and chooses the strategy with the least estimated amount of data to ship. In contrast, Hadoop executes MapReduce jobs always with the same strategy.
For a more detailed comparison of the MapReduce and PACT programming models you can read our paper “MapReduce and PACT - Comparing Data Parallel Programming Models” (see our publications page).
The Pact Compiler
The Pact Compiler is the component that takes a Pact Program and translates it into a Nephele DAG. The Pact Programming Model specifies the parallelism in a declarative way: What are dependencies for parallelization, rather than how to do it exactly. Due to that fact, the process of the translation has certain degrees of freedom in the selection of the algorithms and strategies that are to be used to prepare the inputs for the user functions. Among the different alternatives, it selects the cheapest one with respect to the cost model.
The compiler is found in the project pact-compiler and consist of two main components:
- The Optimizer, which evaluates the different alternatives and selects the cheapest one. The optimizer works on an internal representation of the program DAG and returns its selected best plan in that representation. It is inspired by database optimizers such as the System-R Optimizer, or the Volcano Optimizer Framework.
- The Job Graph Generator, which takes the optimizer's representation and turns it into a Nephele DAG, specifying all parameters according to the optimizer's chosen plan.
Optimizer
The optimizer is contained in the package eu.stratosphere.pact.compiler. The central class is PactCompiler, providing the compile() method that acts as the main entry point for the compilation process. It accepts an instance of a Pact Plan and returns an instance of OptimizedPlan.
The optimizer uses an internal representation of the plan, which is a DAG of nodes as the original Pact Plan. The nodes contain a large set of properties, such as size estimates, cardinalities, cost estimates, known properties of the data at a certain point in the plan, etc. In most cases, the optimizer's nodes correspond directly to nodes in the Pact Plan; however, additional nodes may be inserted, for example for combiners and artificial dams. The classes for the internal representation can be found in eu.stratosphere.pact.compiler.plan.
Optimization Process
The optimization process starts with a preparatory phase, where the optimizer connects to the JobManager and requests information about the available instances. It selects a suitable instance type for the program's tasks and records the amount of memory that the instances have available.
The actual optimization process is inspired by the design of the System-R Optimizer, or the Volcano Optimizer Framework. It is similar to System-R, because it uses a bottom-up approach to enumerate candidates, and it is similar to Volcano, because it uses a generalized notion of so called interesting orders. To understand these concepts, please refer to the papers Access path selection in a relational database management system and The Volcano optimizer generator: Extensibility and efficient search.
Note that the optimizer contains no algorithm for the enumeration of join orders, because a similar degree of freedom is not expressible in the programming model. Currently, the structure of the Pact Plan is fixed and the degrees of freedom are in the different shipping strategies and the local strategies.
In our implementation, the optimization process has three phases, which are schematically depicted in the following picture:
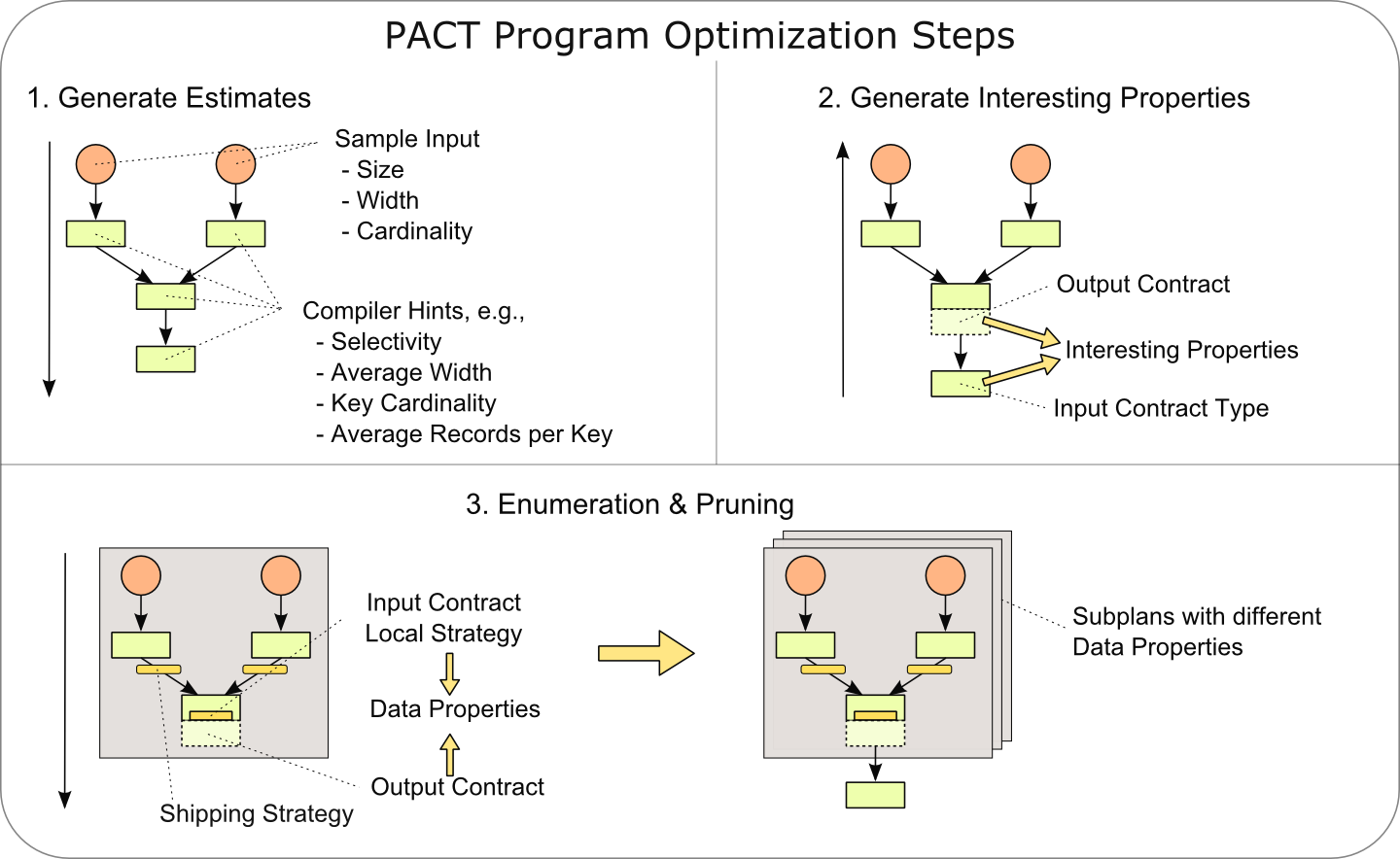
All phases happen as a traversal of the graph defined by the Pact Plan. The traversals start at the data sinks and proceed depth-first, with certain rules. For example, nodes that have more than one successor (which is possible, because we support DAGs rather than trees) traverse only deeper when they have been visited coming from all successors.
Phase 1: The optimizer traverses the plan from sinks to sources and creates nodes for its internal representation. When nodes for the DataSourceContracts are created, it accesses the files, determines their size and samples them to find out how many records they contain. That information acts as the initial size and cardinality estimate. Once all nodes are created, they are connected on the re-ascension of the recursive depth-first traversal. When connecting nodes, the size and cardinality estimates are created based on the predecessors' estimates and the Compiler Hints. In the absence of compiler hints, robust default assumptions are used.
Phase 2: Another traversal generates interesting properties for each node. A node's interesting properties describe the properties of the data that will help successor nodes to execute more efficiently. A Reduce Contract, for example, will be more efficient, if the data is already partition on the key, and lets its predecessors know that by setting partitioning as an interesting property for them. Interesting properties are propagated from the sinks towards the sources, but only, if a certain contract has the potential to generate or preserve them. In general, we must assume that the user function modifies fields in its records. In that case, any partitioning on the keys that existed before the application of the user function, is destroyed. Certain User Code Annotations, however, allow the compiler to infer that certain properties are preserved nonetheless. In phase 2, the compiler also creates auxiliary structures that are required to handle Pact Plans that are DAGs but not trees. Those structures are for example required to find common predecessors for two nodes.
Phase 3: The final phase generates alternative plan candidates, where the Shipping Strategies and Local Strategies are selected. The candidates are generated bottom-up, starting at the data sources. To create the candidates for a node, all predecessors are taken (or all combinations of predecessors, if the node corresponds to a Pact with multiple inputs), and are combined with the different possibilities for shipping strategies and local strategies. Out of all the candidates, the cheapest one is selected, plus all that produce additional properties on the data, that correspond to interesting properties defined in phase 2. That way, it is possible to get plans that are more expensive at earlier stages, but where reusing certain properties makes them overall cheaper.
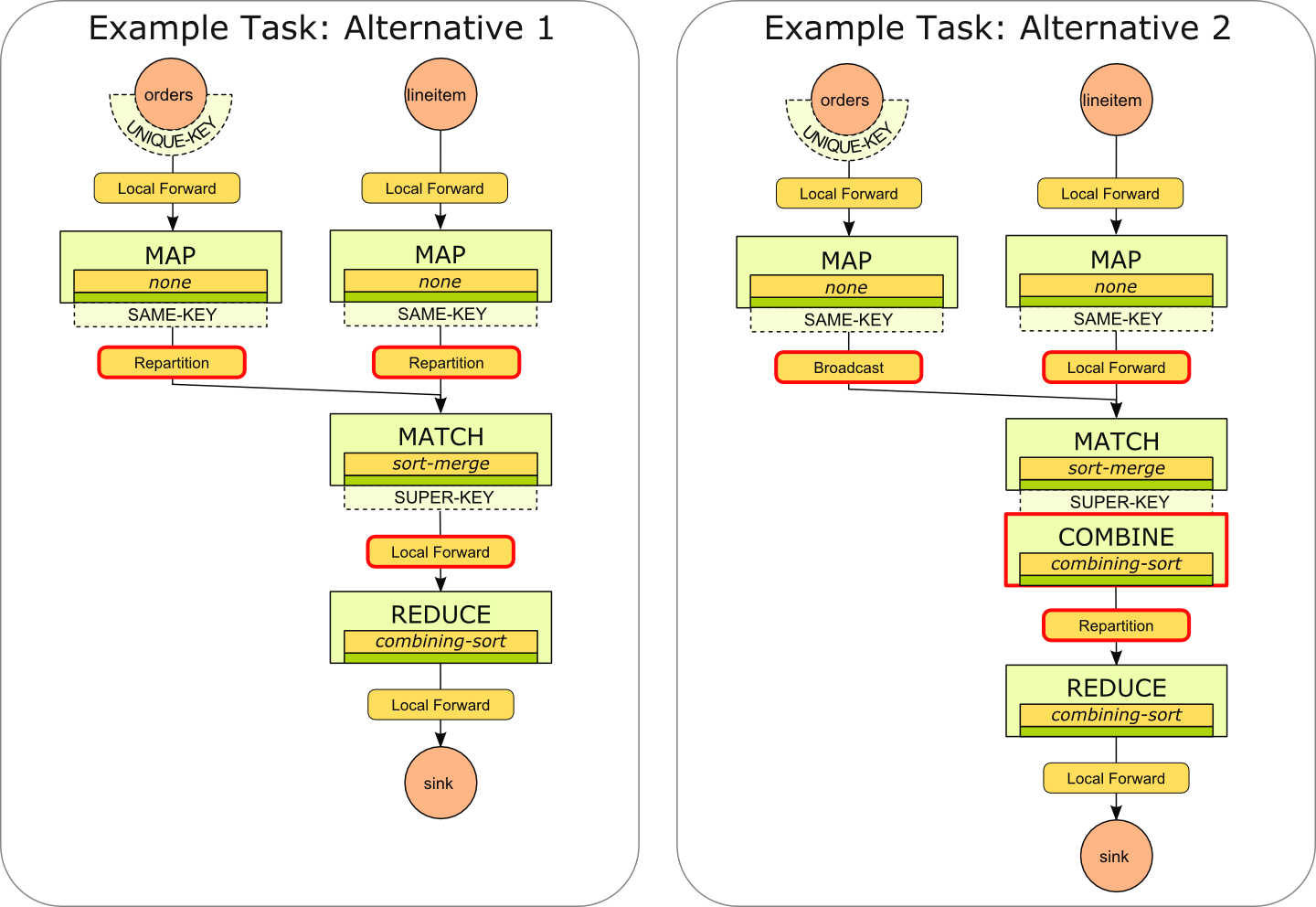
Example
The example below shows two different plans for the simplified TPC-H Query Example. The first candidate represents the optimizer's choice to realize the Match contract though re-partitioning of both inputs. The presence of the User Code Annotations announcing the unmodified fields lets the optimizer infer that the partition still exists after the user function. The succeeding Reduce contract can hence be realized without repartitioning the data. Because no network is involved, the system decides not to use an extra combiner here. The Reduce contract does have to re-sort the data, because the optimizer cannot infer that any order of the Key/value pairs within a partition would be preserved in this case.
The second candidate shows a variant, where the Match contract was realized by broadcasting one input and leaving the other partitioned as it is. Because no suitable partitioning exists after the Match contract, the Reduce contract requires a re-partitioning step.
Cost Model
To compare a plan candidate against others, each plan is attributed with certain costs. Costs are attributed to each node, in order to make sub-plans comparable. Currently, the costs consist of total network traffic and total disk I/O bytes. Because network traffic is typically the major factor in distributed systems, we compare costs primarily by the network traffic, and secondarily by disk I/O. It is possible that costs are unknown, because the estimates they are based on, are unknown. Unknown costs are always larger than known costs, wheres two unknown costs are equally expensive.
Each optimizer node contains values for the costs that it contributes itself, as well as the cumulative costs of itself and all of its predecessors. In the case that some nodes are predecessors on multiple paths in the DAG, their costs contribute only once to the cumulative costs.
Job Graph Generator
The eu.stratosphere.pact.compiler.jobgen.JobGraphGenerator takes an optimized plan and translates it into a Nephele JobGraph.
In a first step, a JobGraph Vertex is created for each optimizer node. The pact-runtime class for the input contract is set as the vertex' code to run. That pact-runtime class executes the Local Strategy that the compiler selected for that Pact. Parameters like the stub class name, or the amount of memory to use for the runtime algorithms, are set in the task's configuration.
The Shipping Strategies selected by the compiler are expressed in the wiring of Job Vertices. In a second step, the Job Graph Generator connects the vertices through channels as described in the optimized plan. Three parameters are set here:
- The channel type (in-memory or network) is assigned based on the co-location of tasks. In general, in-memory channels are used to connect two job vertices whenever the optimizer picked the forward shipping strategy, and the number of computing instances is the same for both of them. In that case, the vertices also share the same computing instance. In all other cases, namely when a connection re-partitions the data, broadcasts it, or redistributes it in any way over a different number of machines, a network channel is used.
- The behavior of the channels during parallelization is defined. For some channels, it is sufficient if they connect the i'th parallel instance of one vertex to the i'th instance of the other vertex. That is called a pointwise pattern and is typically used for forward shipping strategies. For strategies like partitioning and broadcasting, the channels need to connect every parallel instance of one job vertex with every parallel instance of the other job vertex. That is called a bipartite pattern. The type of connection pattern is also written into the task configuration.
- The strategy with which a task selects the channel it wants to send a datum to, like round-robin distribution, hash-partitioning, range-partitioning, or broadcasting.
Example
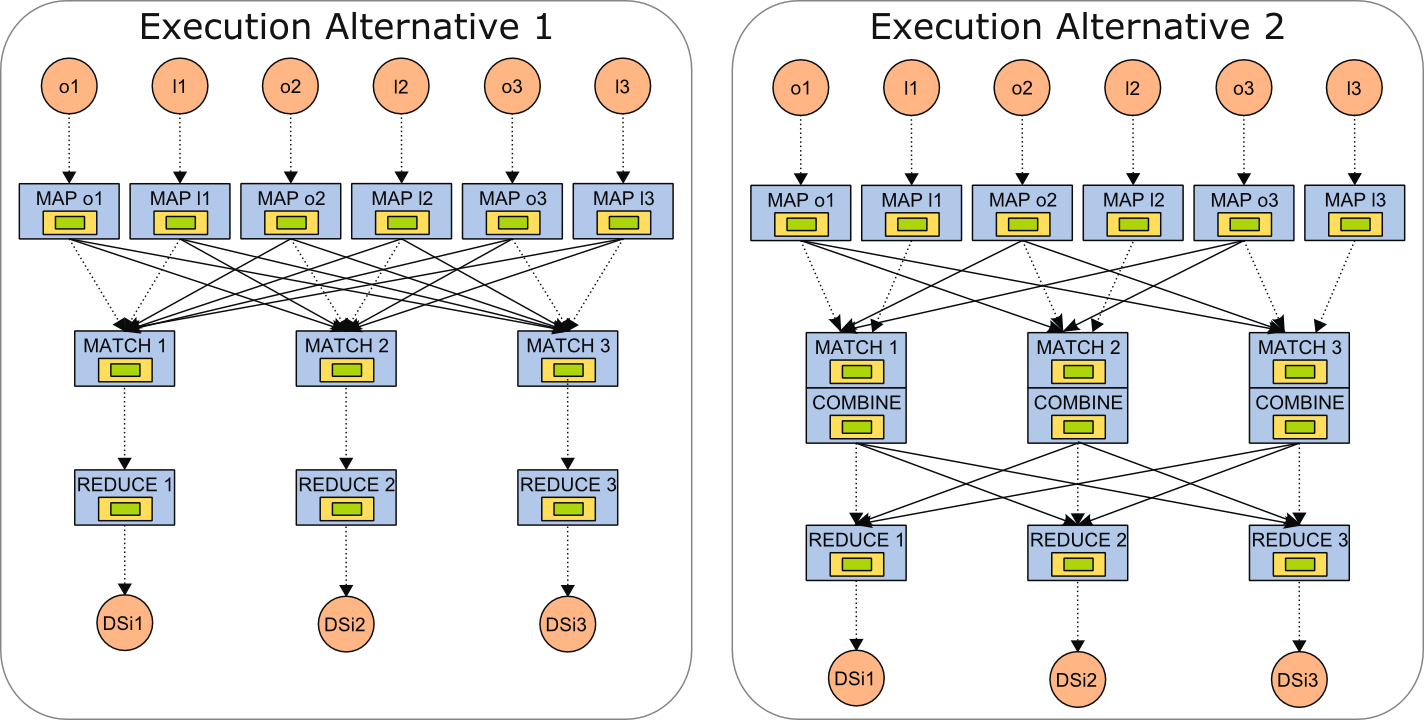
The above example shows the parallel dataflow (degree of parallelism is 3) created for the two example alternatives that were used to illustrate the optimizer's behavior. The solid lines are network channels, the dotted lines are in-memory channels. Note that in alternative one, for both Map Pacts, every instance connects to every instance of the Match Pact (bipartite pattern), because a repartitioning happens on both the Match's inputs. All other connections are pointwise connections. In alternative two, only the parallel instances of one Map Pact use the (bipartite pattern), namely those that broadcast their data. The same pattern is also used between the Combine and Reduce step, for repartitioning.
- PACT Components
PACT Task Execution Strategies
Data analysis tasks implemented with the PACT programming
model
are declaratively specified with respect to data parallelism. The PACT
Compiler
optimizes PACT programs and chooses strategies to execute the program
that guarantee that all Parallelization Contract are fulfilled.
Execution strategies can be divided into Shipping
Strategies
that define how data is shipped over the network and Local
Strategies
that define how the data is processed within a Nephele subtask.
The PACT Web
Frontend
and the PACT Command-Line
Client
feature the displaying of compiled PACT programs, such that the chosen
execution strategies can be checked.
This page describes the execution strategies which are currently
available to the PACT Compiler.
Shipping Strategies
Shipping Strategies define how data is shipped between two PACT tasks.
Forward
The Forward strategy is used to simply forward data from one tasks to
another. The data is neither partitioned nor replicated. If the degree
of parallelism is equal for the sending and receiving task, in-memory
channels are used. In-memory channels are also used, if the same number
of computing instances are used for the sending and receiving task. For
example if five computing instances are used, the sender task has five
parallel instances (one per computing instance), and the receiver task
has 10 parallel instances (2 per computing instance), in-memory channels
are also applicable. Otherwise, the compiler will use network channels.
The connection pattern used for those channels is point-wise (a sending
tasks is connected to max(1,(dop,,receiver,, / dop,,sender,,)) receiving
tasks and a receiving tasks is connected to max(1,(dop,,sender,, /
dop,,receiver,,)) sending tasks.
The Forward is usually used in the following cases:
- connect a Map contract
- connect a DataSink contract (if no final sorting is requested)
- reuse an existing partitioning (e.g., for Reduce, Match, and CoGroup)
- connect the non-broadcasting input of an Match or Cross
Repartition
The Repartition shipping strategy is used to distribute data among subtasks. Thereby, each data record is shipped to exactly one subtask (data is not replicated). The Repartition strategy uses a partitioning function that is applied to the Key of an !KeyValuePair to distinguish to which subtask the pair is shipped. Different partitioning functions have different characteristics that can be exploited to improve data processing. The most commonly used partitioning functions are:
- hash-based: Pairs with equal keys are shipped to the same subtask. Good hash-based partitioning functions frequently provide good load balancing with low effort.
- range-based: Ranges over a sorted key domain are used to group Pairs. “Neighboring” pairs are send to the same subtask. In order to ensure good load balancing, the distribution of the keys must be known. Unknown distributions are usually approximated with sampling which produces a certain overhead.
- round-robin: Pairs are evenly distributed of all subtasks. That produces perfect load balancing, with respect to the number of records, but no further usable properties on the data are generated.
The Repartition strategy is realized using a bipartite distribution pattern (each sending subtask is connected to each receiving subtask) and network channels.
The Repartition strategy is typically used to establish a partitioning such as for:
- a Reduce contract
- a CoGroup contract
- a Match contract
Broadcast
The Broadcast shipping strategy is used to fully replicate data among
all subtasks. Each data record is shipped to each receiving subtask.
Obviously, this is a very network intensive strategy.
The Broadcast strategy is realized through network channels and a
bipartite distribution pattern (each sending subtask is connected to
each receiving subtask).
A Broadcast is used for example in the following cases:
- connect one side of a Cross contract. The other side is connected with a Forward strategy.
- connect one side of a Match contract. The other side is connected with a Forward strategy.
Local Strategies
Local Strategies define how data is processed within a Nephele subtask.
Sort
The Sort strategy sorts records on their keys. The sort is switched from an in-memory sort to an external sort-merge strategy if necessary.
Sort is for example used for Reduce contracts (streaming the sorted data, all pairs with identical keys are grouped and handed to the reduce() stub method) or sorted data sinks.
Combining Sort
The Combining Sort strategy is similar to the Sort strategy. However, in contrast to Sort, the combine() method of a Reduce stub is applied on sorted subsets and during merging, in order to reduce the amount of data to be processed afterward. This strategy is especially beneficial for large number_of_records / number_of_keys ratios. The Combining Sort strategy is only applicable for Reduce tasks that implement the combine() method (see Write PACT Programs).
Combining Sort is used for:
- Reduce contracts: Intermediate results are reduced by combine() during sorting to a single pair per key.
- Combine tasks: Data is reduced during sorting. The sorted pairs (a single pair per key) are shipped to a Reduce task using the Repartitioning shipping strategy.
Sort Merge
The Sort Merge strategy operates on two inputs. Usually, both inputs are sorted by key and finally aligned by key (merged). The Sort Merge strategy comes in multiple variations, depending on whether none, the second, the first, or both inputs are already sorted. The PACT Compiler derives existence of the sorting property from existing properties (resulting from former sorts), Output Contracts, applied Shipping Strategies.
The Sort Merge strategy is applied for:
- Match tasks: When merging both inputs, all combinations of pairs with the same key from both inputs are built and passed to the match() method.
- CoGroup tasks: When merging both inputs, all values that share the same key from both inputs are passed to the coGroup() method.
Hybrid-Hash
The Hybrid Hash strategy is a classical Hybrid Hash Join as in Relational Database Systems. It reads one input into a partitioned hash table and probes the other side against that hash table. If the hash table grows larger than the available memory, partitions are gradually spilled to disk and recursively hashed and joined.
The strategy is used for:
- Match in most cases when no inputs are pre-sorted.
Block-Nested-Loops
The Block-Nested-Loops strategy operates on two inputs and builds the Cartesian product of both input's pairs. It works as follows: One input is wrapped with a resettable iterator, which caches its data in memory, or on disk, if necessary. The other input is read block-wise, i.e. records are read into a fixed sized memory block until it is completely filled. One record after another is read from the resettable iterator and crossed with all values in the fixed-sized memory block. After all records in the resettable iterator have been crossed with all values in the memory block, the block is filled with the next values of the unfinished input and the resettable iterator is reset. The Nested-Loop is finished after the last records have been read into the memory block and have been crossed with the resettable iterator.
The Block Nested-Loops strategy comes in two variations, that distinguish which input is read into the resettable iterator and which input is read block-wise. The Blocked Nested-Loop strategy is usually much more efficient than the Streamed Nested-Loop, due to the reduced number of resets and disk reads (if the resettable iterator was spilled to disk). However, it destroys the order on the outer side, which might be useful for subsequent contracts.
The Block Nested-Loops is used for:
- Cross tasks to compute the Cartesian product of both inputs.
- Match if a key occurs a large number of times.
Streamed Nested-Loops
The Streamed Nested-Loops strategy operates on two inputs and builds the Cartesian product of both input's pairs. It works as follows: One input is wrapped with a resettable iterator, which caches its data in memory, or on disk, if necessary. The other input is read one record at a time. Each record is crossed with all values of the resettable iterator. After the last record was read and crossed, the Nested-Loop finishes.
The Streamed Nested-Loops strategy comes in two variations, that distinguish which input is read into the resettable iterator and which input is read and crossed as stream. The Streamed Nested-Loop strategy is usually much less efficient than the Blocked Nested-Loop strategy, especially if the resettable iterator cannot cache its data in memory. In that case, it causes a significantly larger number of resets and disk reads. It does, however, preserve the order on the outer side, which might be useful for subsequent contracts.
The Streamed Nested-Loops is used for:
- Cross tasks to compute the Cartesian product of both inputs.
PACT Memory Management
Many of the local execution strategies such as sorting require main memory. Usually, the amount of assigned memory significantly affects the performance of the strategy. Therefore, memory assignment is an important issue in data processing systems.
In the Stratosphere system, the PACT Compiler is responsible for assigning memory to local strategies. The current implementation of memory assignment is straight-forward and is applied after the best execution plan was determined. It works as follows:
- All memory consuming strategies are enumerated. A strategy has a fixed weight that represents its requirements (for example, SORT_BOTH_MERGE which sorts both inputs requires twice as much memory as SORT_FIRST_MERGE which sorts only the first input).
- Minimum amount of available available memory among all instances / TaskManagers is determined.
- The memory is split among all memory consuming local strategies according to their weight.